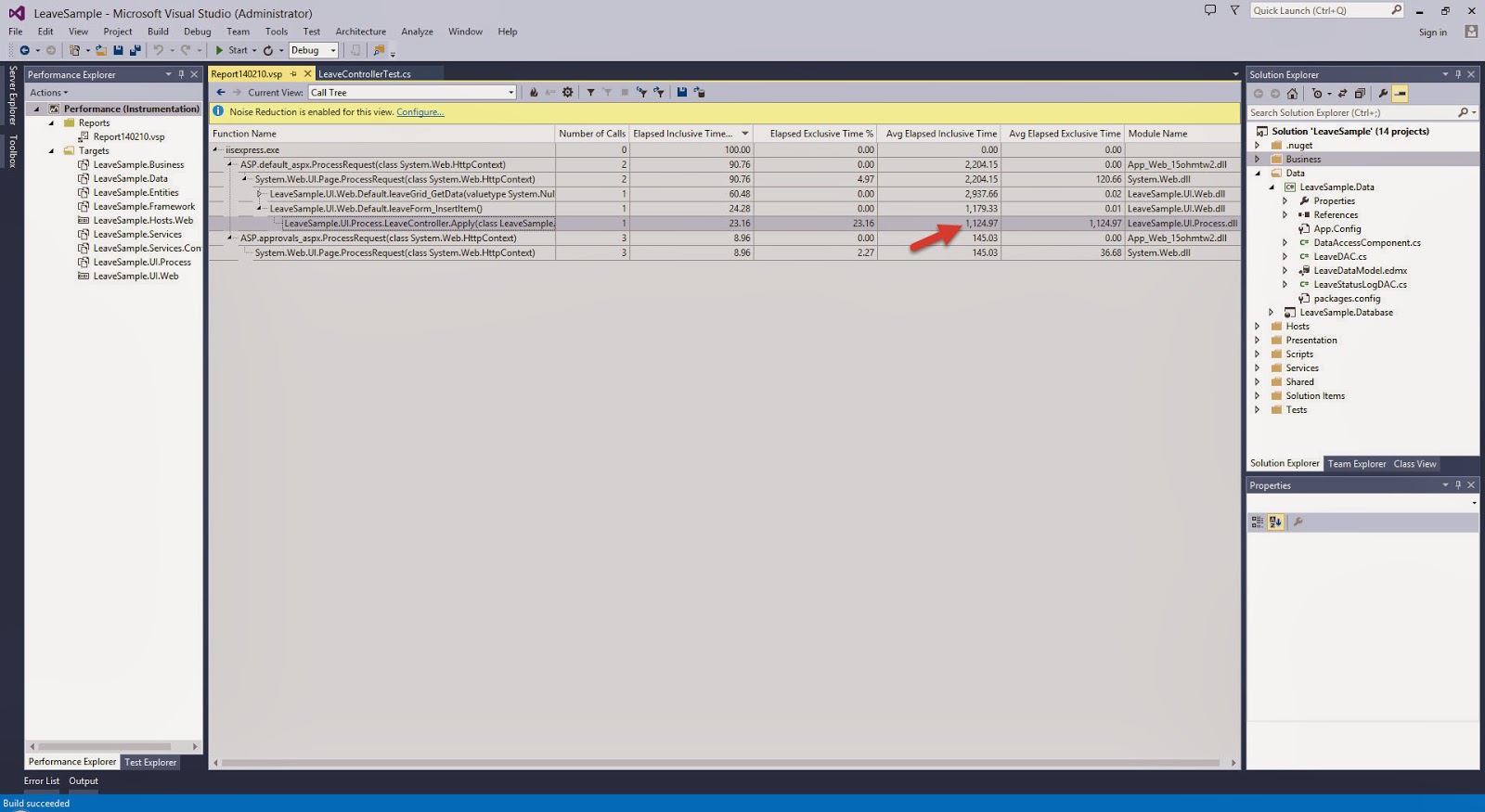
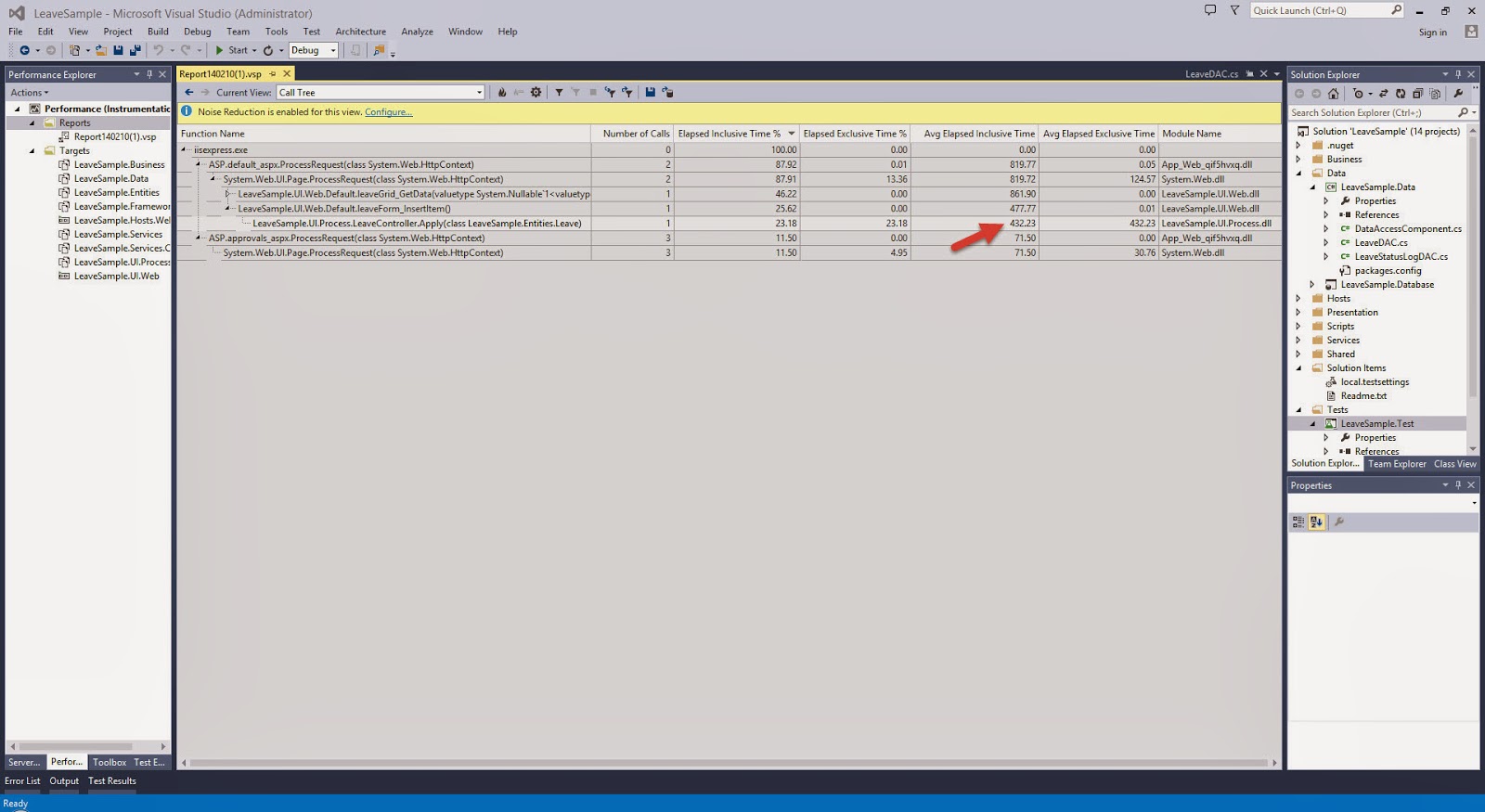
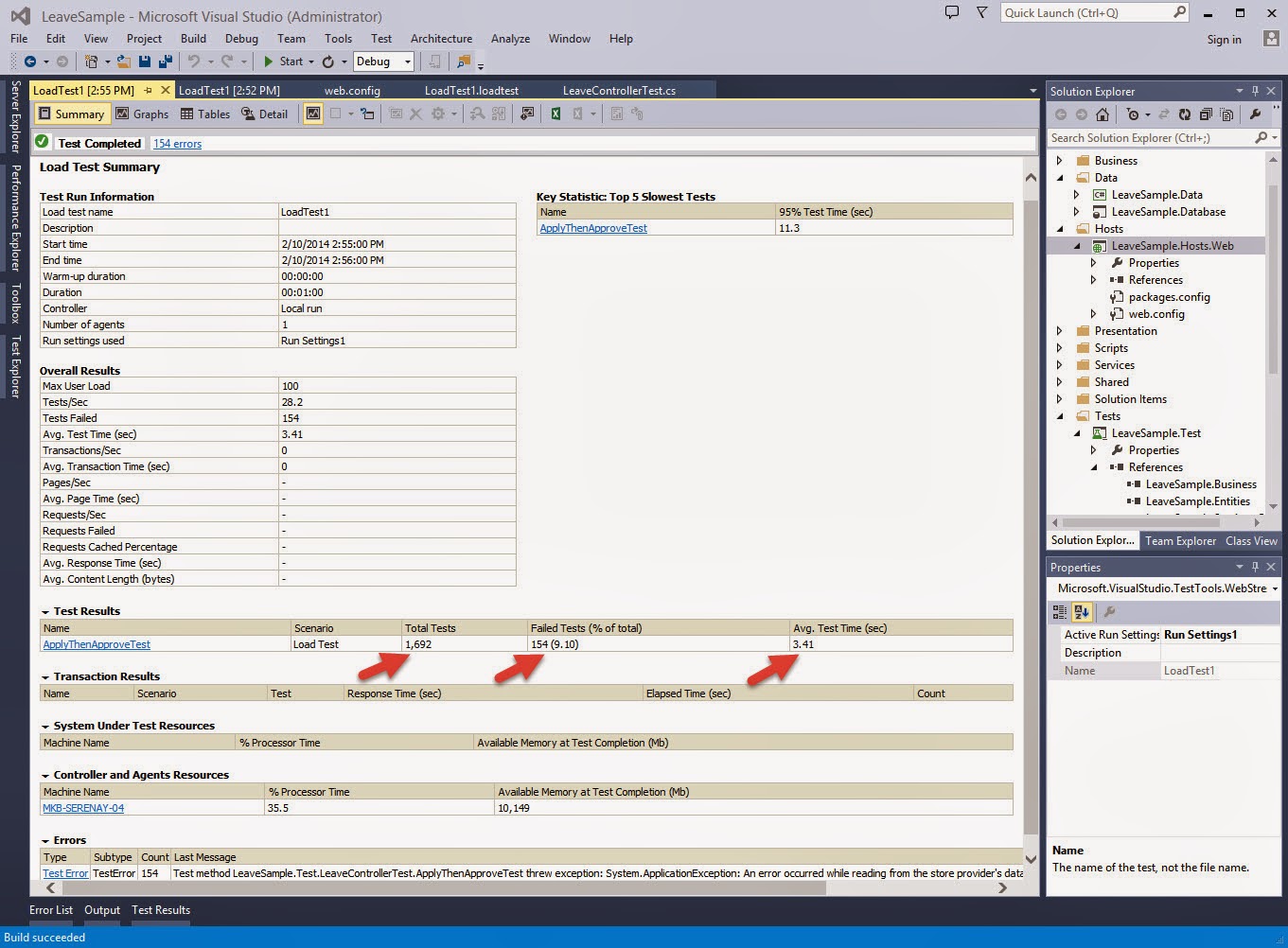
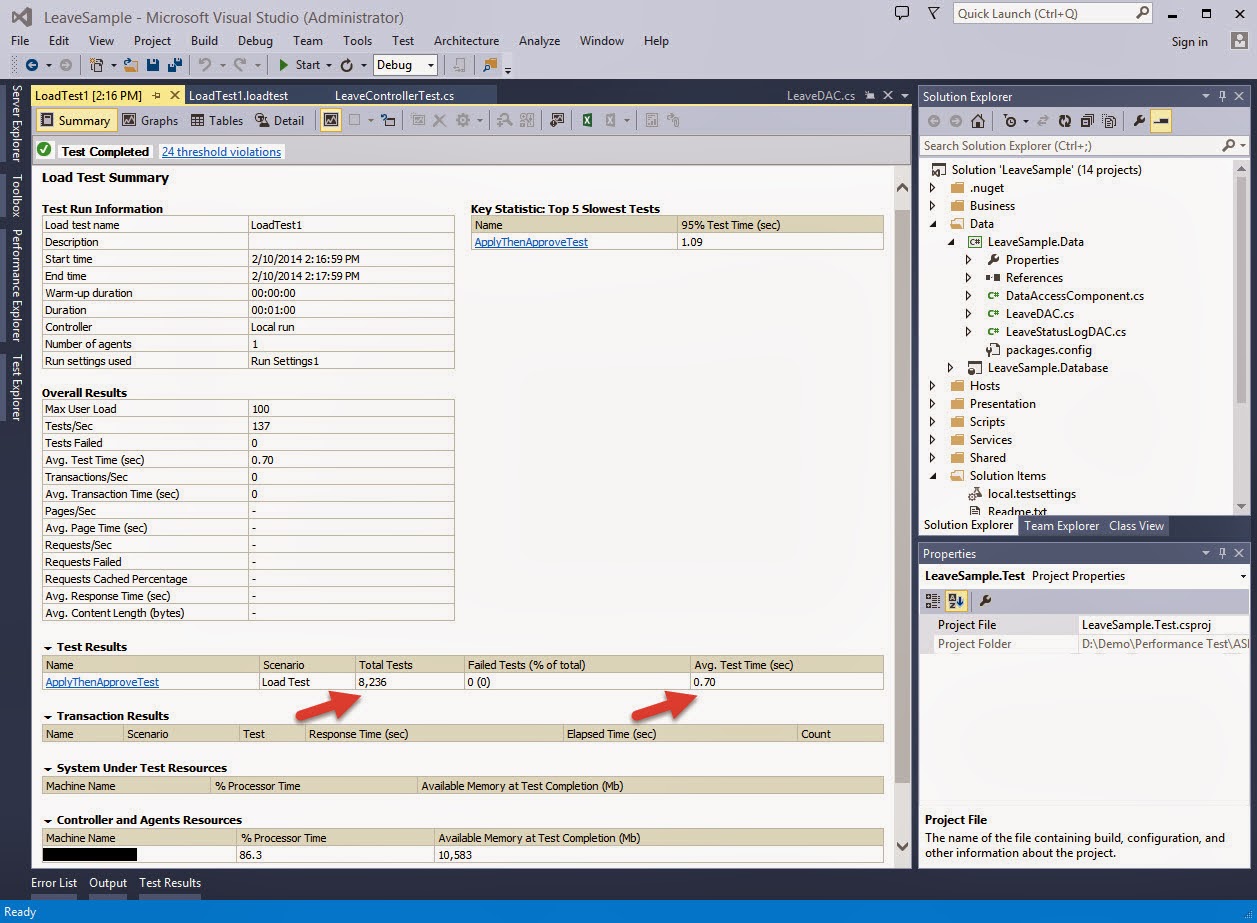
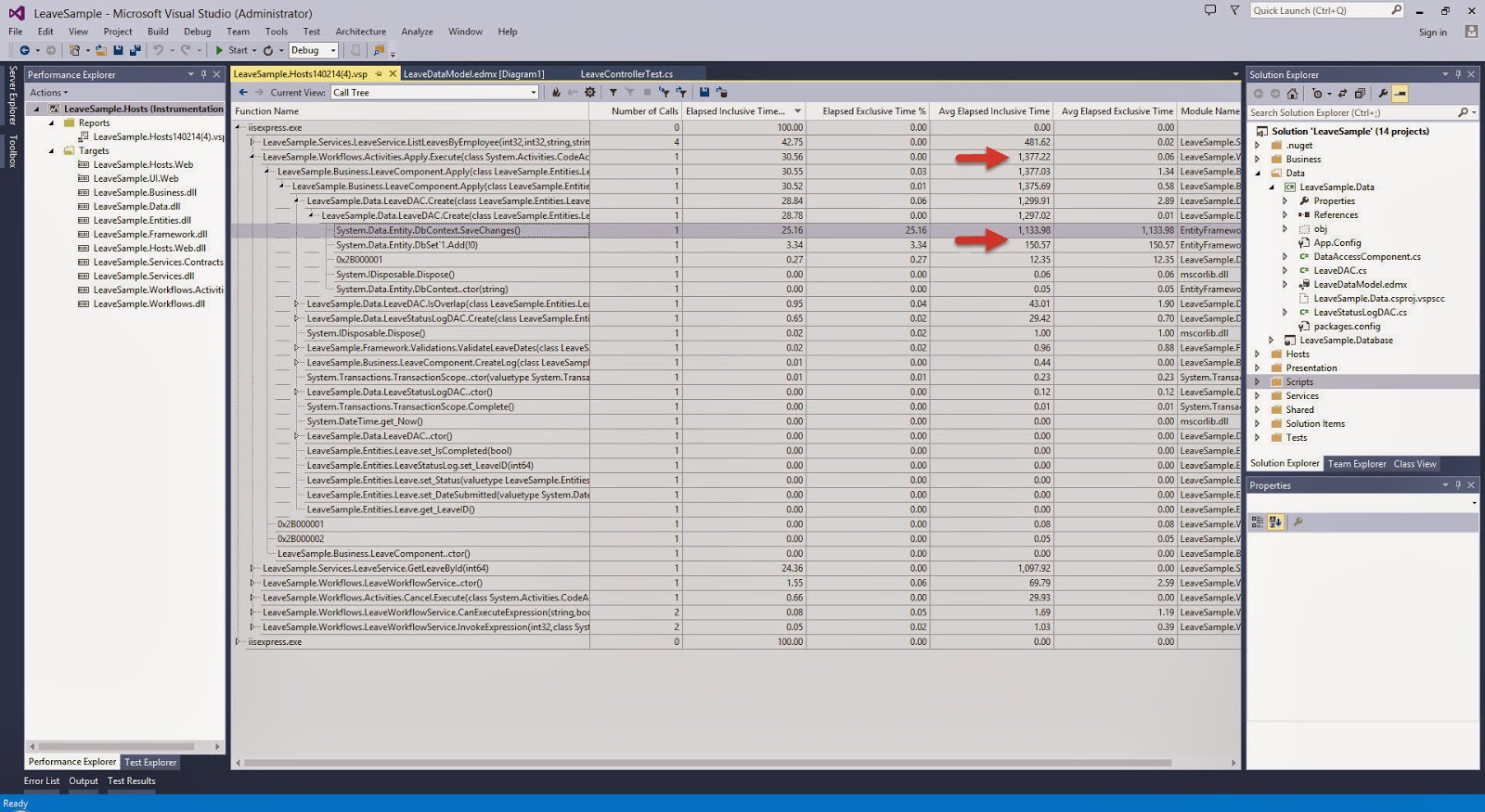
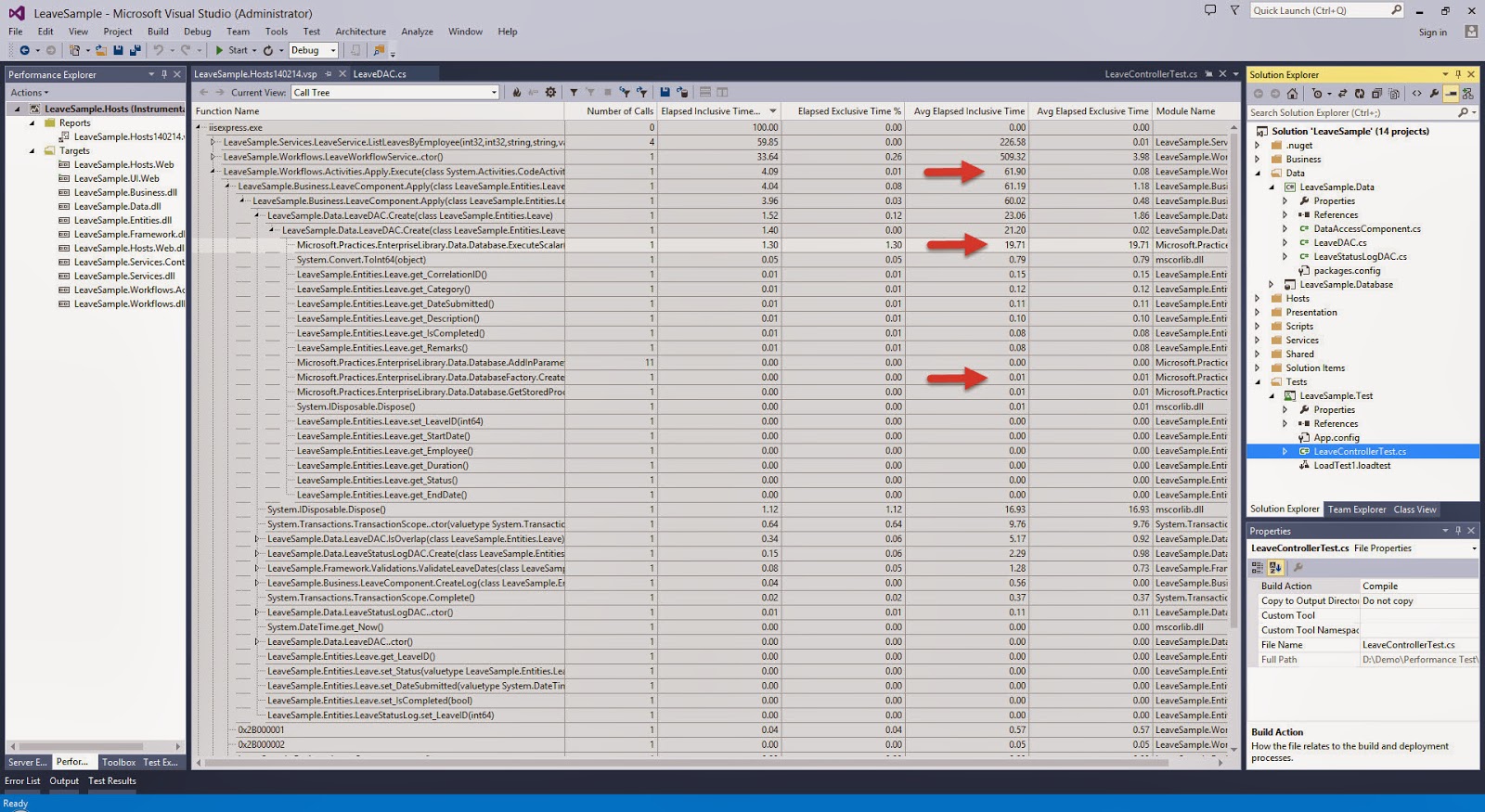
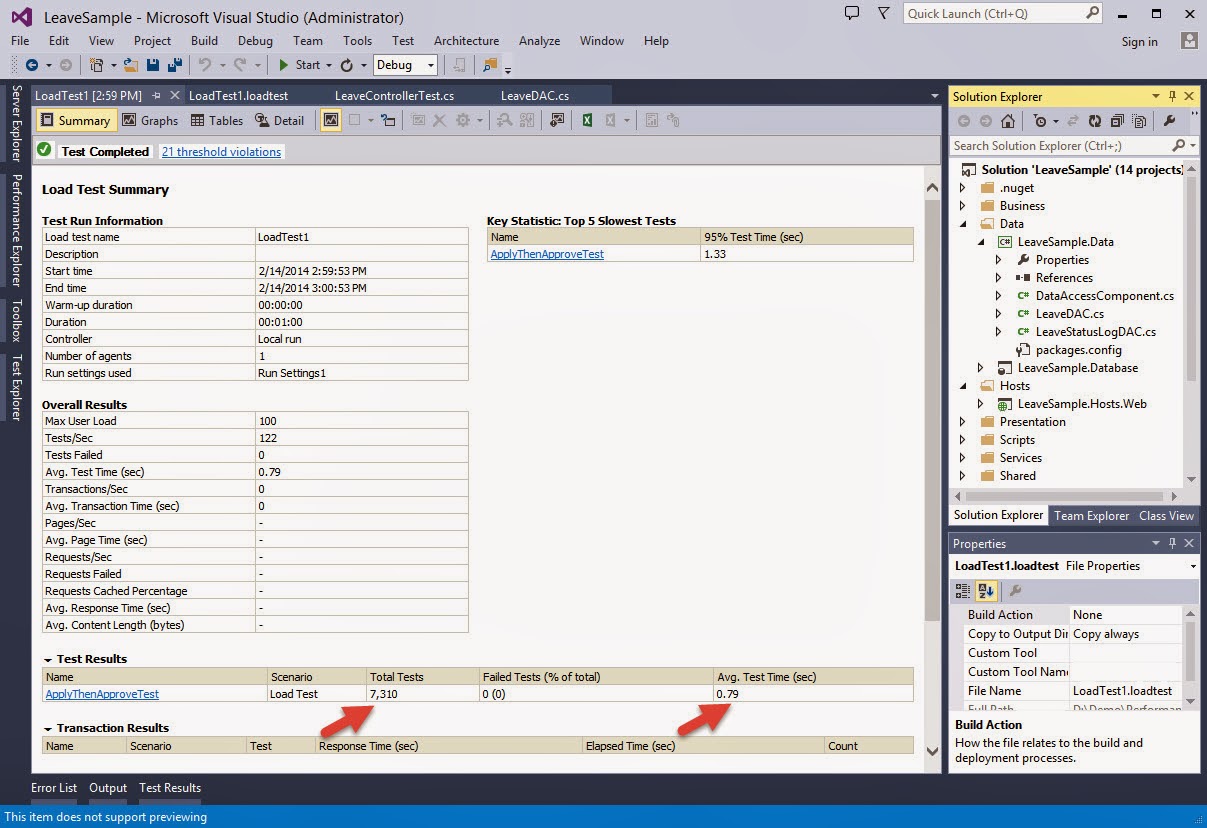
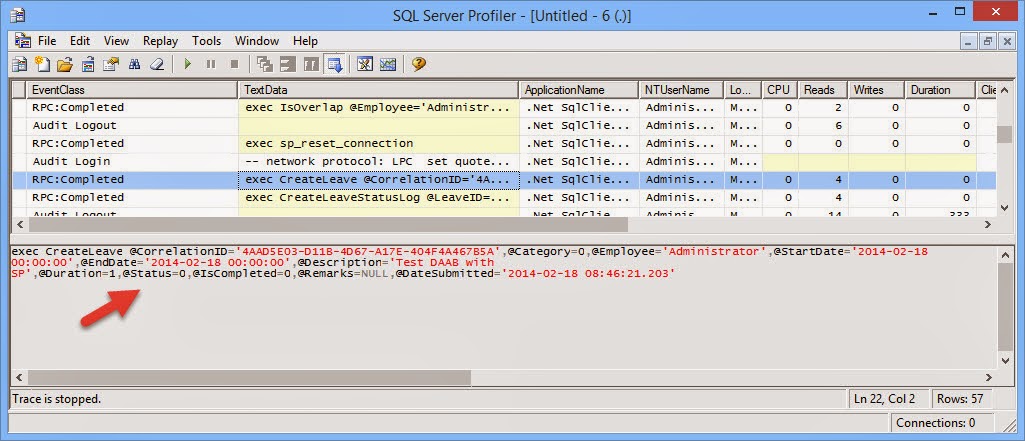
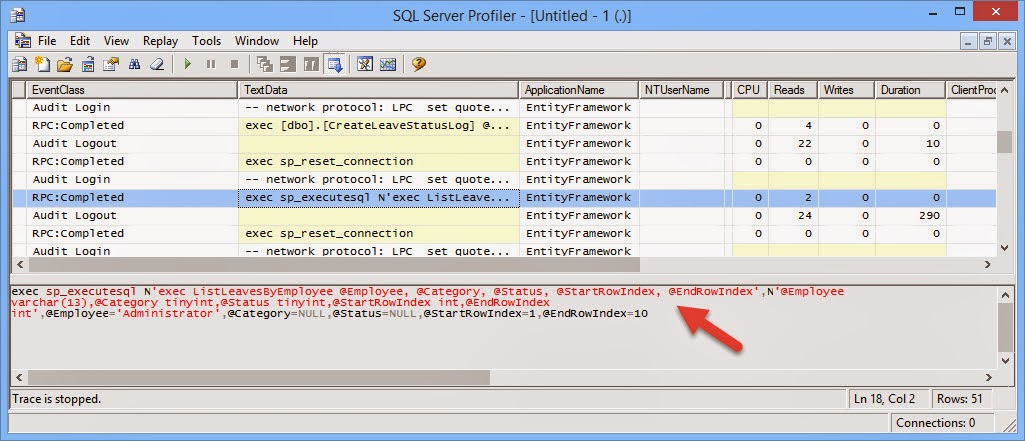
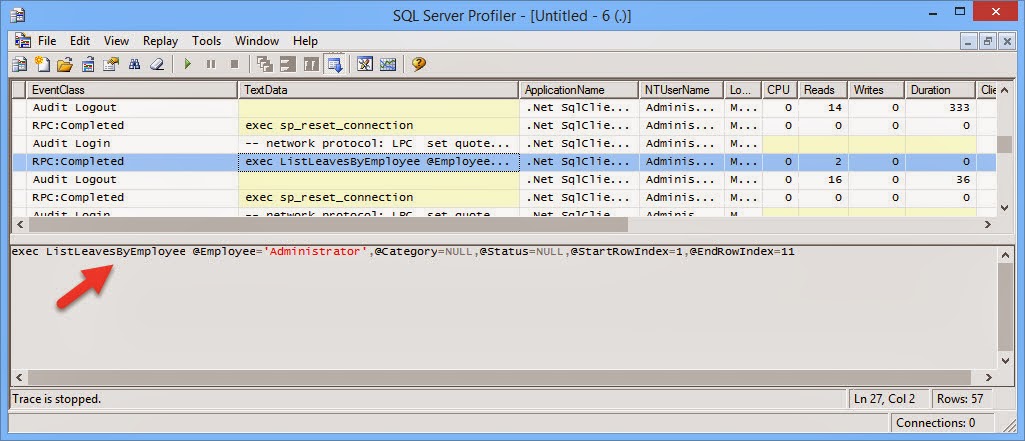
I have always been an advocate for the Layered Architecture Design Pattern. Since the day I was exposed to it, I have always tried to practice it in my application development.
The Layered Architecture Design Pattern promotes the concept of separation of concerns where code of similar responsibilities are being factored into layers. It is purely a logical design but it can be combined with physical design patterns such as the N-tier architecture to deliver highly scalable and impressive distributed enterprise applications.
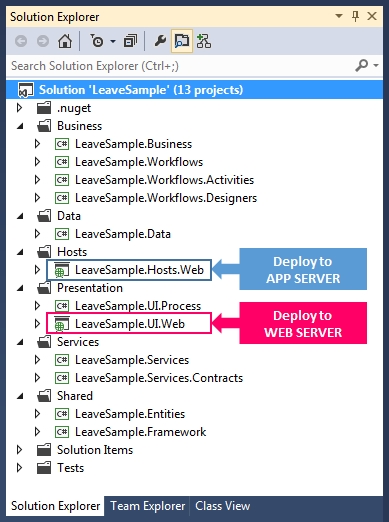
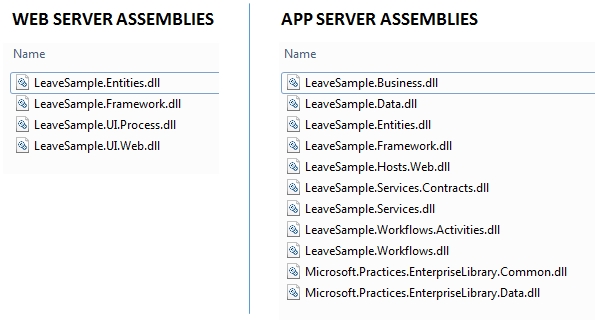
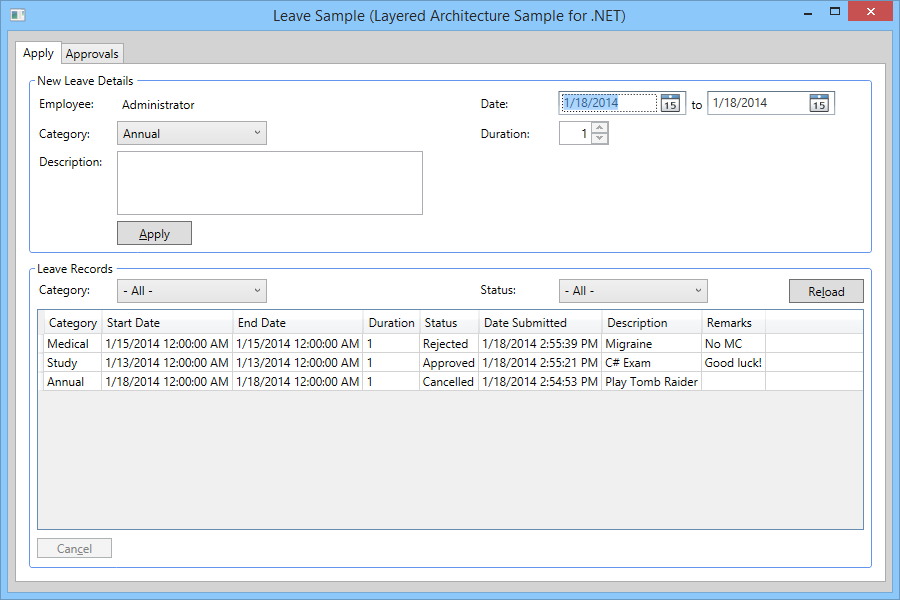
Having followed the Microsoft Application Architecture Guide 2nd Edition and its previous edition, I have always tried to materialize the concepts in code with the .NET technologies available at the time. The result of such work can be seen in Layered Architecture Sample for .NET. I actually started testing out the concepts with .NET Remoting but when I published the samples, I have already started learning WCF.
Lately, I realized that many people are starting to adopt the Layered Architecture Design Pattern and I also noticed many newer .NET technologies have emerged. I would like to take this opportunity to provide an article on my thoughts and perhaps an updated version of the Layered Architecture Design Pattern for .NET.
![]()
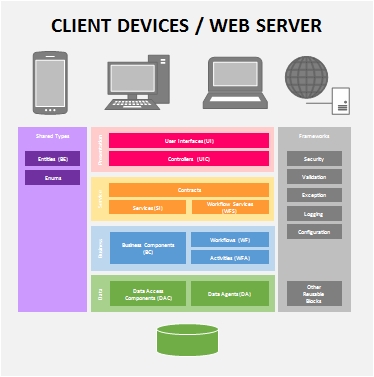
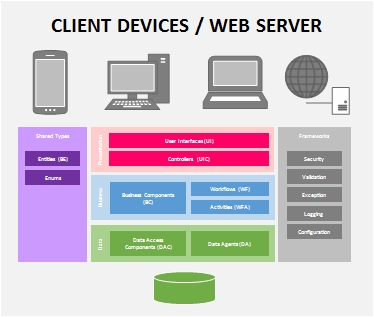
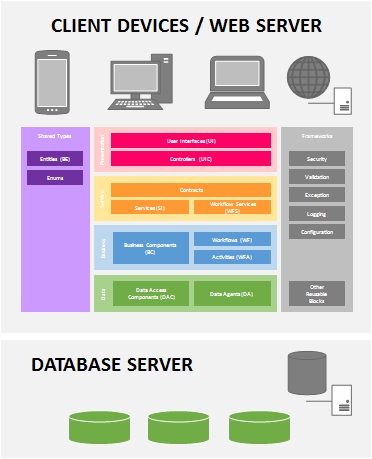
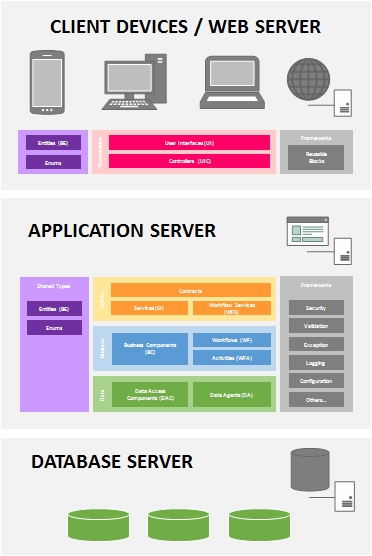
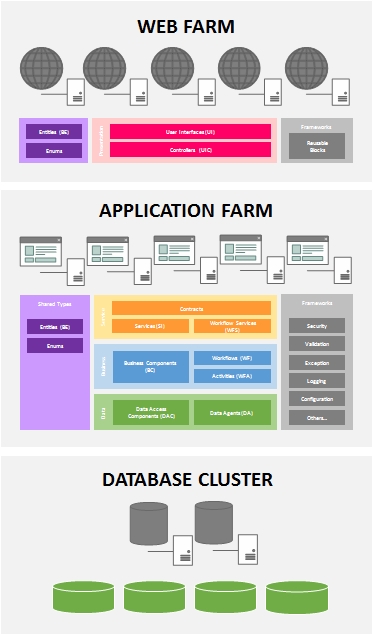
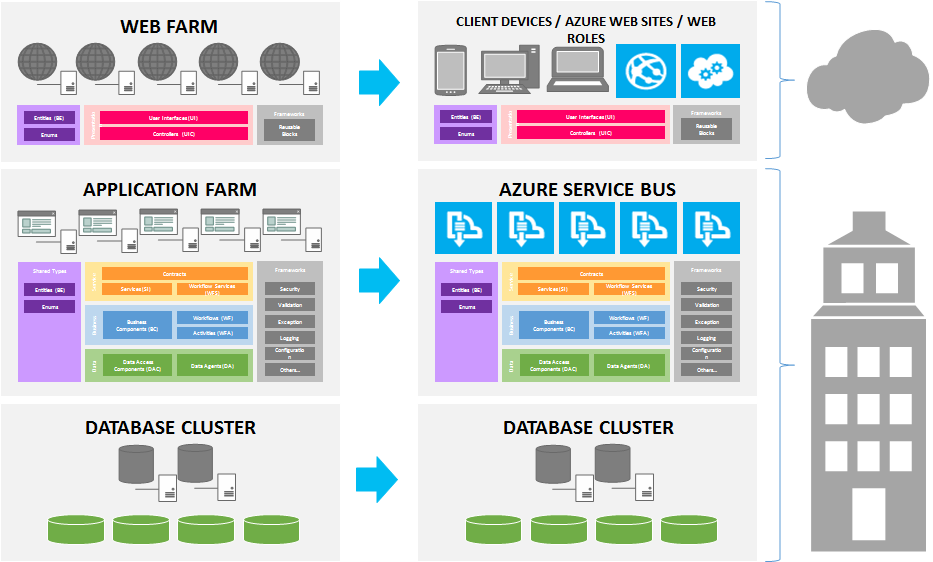
Conceptually, this is how I visualized the Layered Architecture Design Pattern to be, in today's modern world. There are of course more sophisticated visualizations but I purposely kept it simple and near to what most of us are familiar with (and closer to the books).
Data Layer (a.k.a. Data Access Layer or DAL)
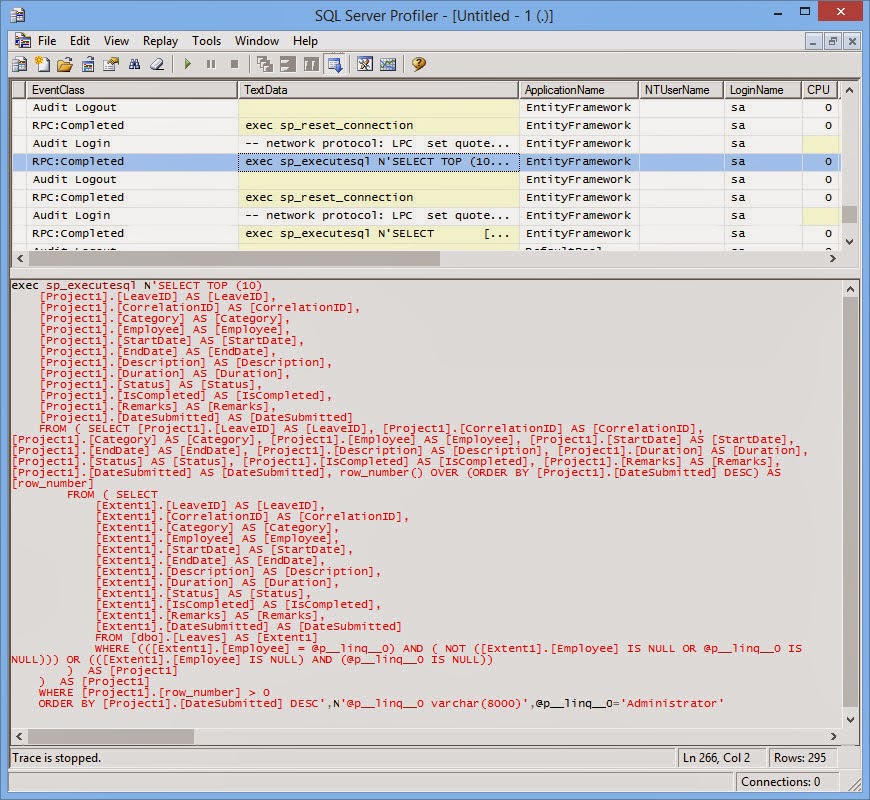
The data layer is where we keep our components that handle the insertion (Create), selection (Read), modification (Update) and deletion (Delete) of data - or better known as CRUD operations. While it is simplistic to think that data usually comes from a database, in reality, data can come from or go into various sources as well i.e. Web Services, Flat Files, Message Queues, XML files, SharePoint Lists etc.
Therefore, components that deal with database tables are called Data Access Components (DAC) and those that deal with other data sources will be called Data Agents (DA) i.e. Service Agents, File Agents, Queue Agents etc.
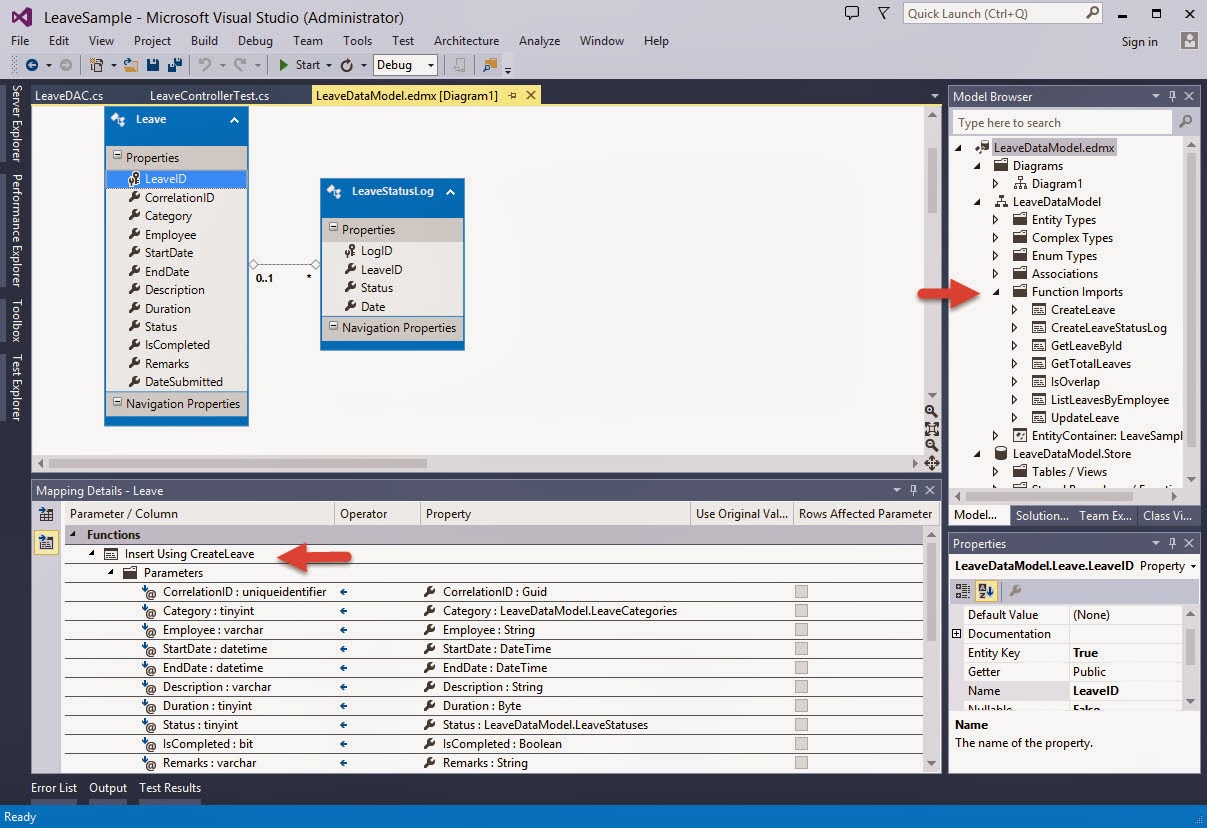
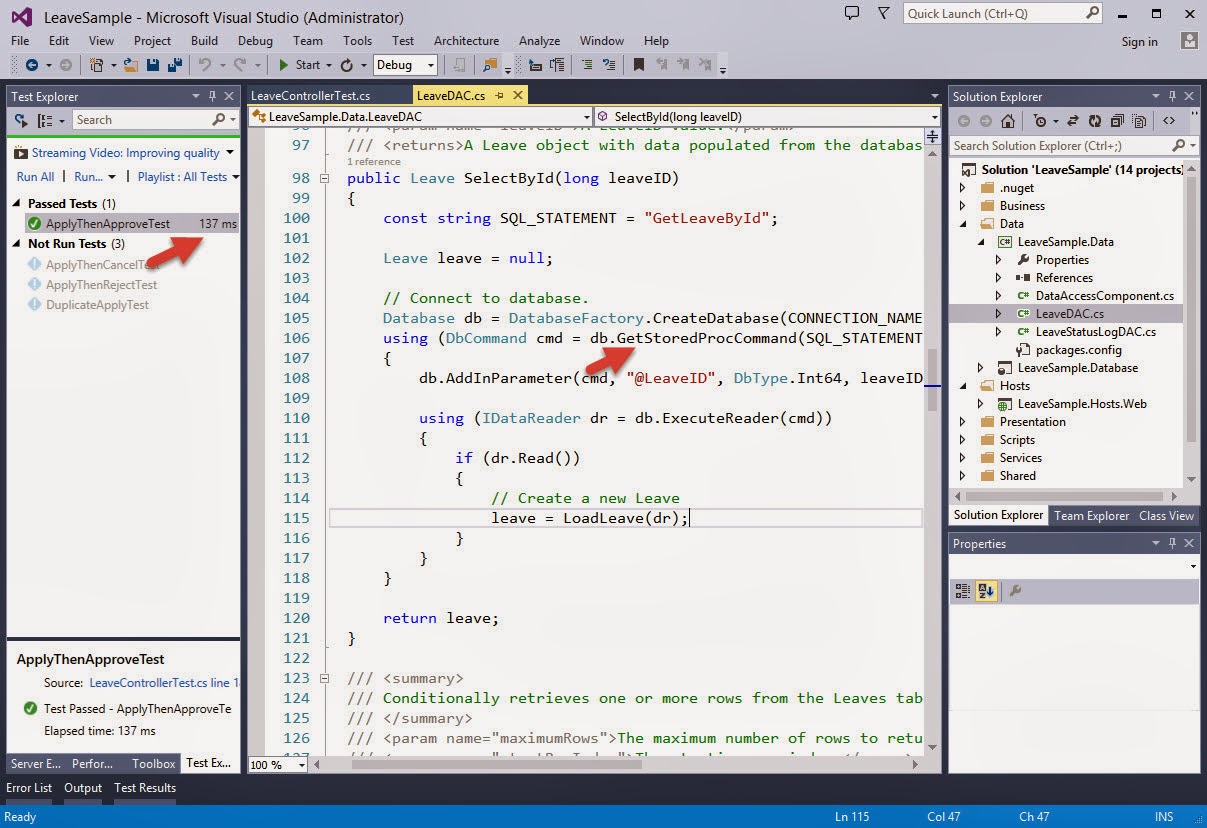
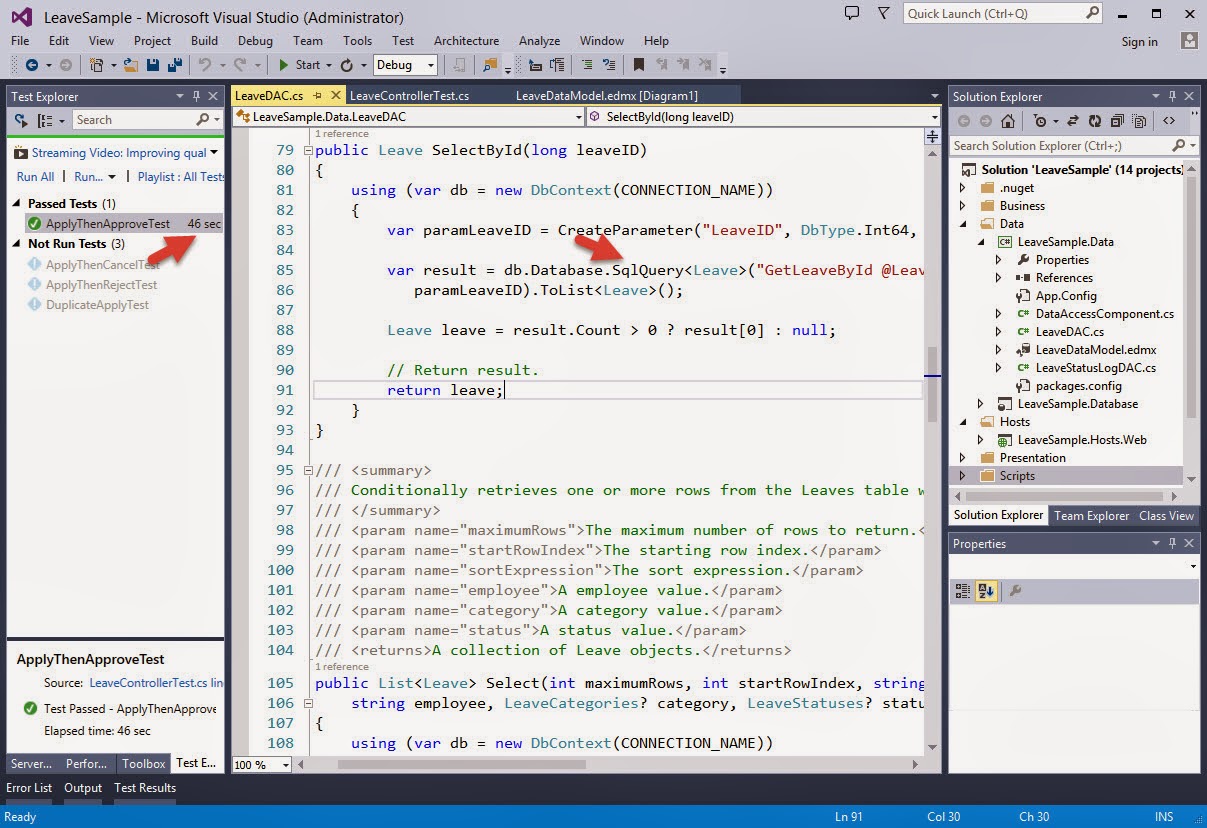
Data Access technologies that you can use in .NET are ADO.NET, Enterprise Library Data Access Application Block and ADO.NET Entity Framework.
Business Layer (a.k.a. Business Logic Layer or BLL)
The business layer is where the heart of our application resides. It contains all the processing logic to make the application possible. The Business Component (BC) is where you put these processing logic where each can be coded into independent business methods. Traditionally, we are required to chain-up the business methods manually in code to form the business process but fortunately today, we have workflow technologies.
If you can isolate each business method to function on its own, you can exposed them as a Workflow Activity (WFA). These workflow activities can then be used by a Workflow (WF) component to orchestrate the business processes.
Windows Workflow Foundation is the workflow technology that can be used in .NET.
Services Layer (a.k.a. Messaging Layer)
The services layer plays the most important role in the architecture to enable the functionality of the system to be exposed to client and external applications. It is also the key to achieving multi-platform and interoperable solutions.
Services components expose the functionality of business components or workflows via Contracts. In the Services-Orientation world, contracts are the interfaces where both service providers and service consumers agree on and should be immutable. Contracts are not just limited to describe the service and its operations but can also be used to describe the messages (i.e. Message Contracts) that are to be sent and received.
I use Services (SI) to represent components that expose business components directly and Workflow Services (WFS) to represent services that expose workflow functionality. The reason for this is because Workflow Services are usually long running and may have special requirements such as correlation.
Services technologies that can be used in .NET are Windows Communication Foundation (WCF), Workflow Services and ASP.NET WEB API.
Presentation Layer (a.k.a. User Interface Layer)
The presentation layer should not need much explanation. It is basically the part of the system where the user interacts with. Your screens, forms, web pages and reports are all User Interfaces (UI) which are part of the presentation layer. User Interfaces can make use of User Process Components or Controllers (UIC) to communicate with the back-end and to navigate or process the UI.
A carefully designed layered application should be able to support any form (or platform) of UI. If you are able to encapsulate all your processing logic behind the service layer, you can have whatever UI (Web, Desktop or Mobile) that you desire to connect to it - even UI-less external systems.
Presentation technologies that can be used in .NET are Windows Presentation Foundation (WPF), Silverlight, ASP.NET Web Forms, ASP.NET MVC, Windows Phone, Windows Store Applications and Windows Forms.
Shared Types
So far we have covered the components in all the layers but we have not yet discussed about how data is being passed between them. Traditionally, .NET developers use DataSets and DataTables but these are heavy-weight objects. Entities are Plain-Old-CLR-Objects (POCO), which means they are just classes with properties that ferry data across your layers. Sometimes, they are also called Data Transfer Objects (DTO).
It is recommended that you do not put any processing logic inside the Entities. If there are any processing logic, they should be placed in the business components. The reason is because when entities are being serialized to non .NET platforms, your processing logic may not carry over.
Some property values in entities can be represented using Enumerations (Enums) for easier readability. Example, it is much better to strongly-type your Status property with an Enum to show meaningful statuses such as Pending, Cancelled or Approved, instead of 0, 1 or 2.
Frameworks (a.k.a. Cross-cutting Framework)
In every system, there are bound to be code that can be shared across all the layers i.e. logging, auditing, validation and etc. You can treat these components as Framework components that can be shared by any of the layers. Framework components can be from 3rd-party (i.e. Microsoft Enterprise Library) or any custom in-house built components i.e. string manipulation functions, custom validation functions, extension methods etc.
Conclusion
I hope the explanation in this article can be a useful foundation for adopting the Layered Architecture Design Pattern. If you wish to see code samples on how it can be implemented with .NET technologies, please feel free to visit Layered Architecture Sample for .NET.
The Layered Architecture Design Pattern promotes the concept of separation of concerns where code of similar responsibilities are being factored into layers. It is purely a logical design but it can be combined with physical design patterns such as the N-tier architecture to deliver highly scalable and impressive distributed enterprise applications.
Having followed the Microsoft Application Architecture Guide 2nd Edition and its previous edition, I have always tried to materialize the concepts in code with the .NET technologies available at the time. The result of such work can be seen in Layered Architecture Sample for .NET. I actually started testing out the concepts with .NET Remoting but when I published the samples, I have already started learning WCF.
Lately, I realized that many people are starting to adopt the Layered Architecture Design Pattern and I also noticed many newer .NET technologies have emerged. I would like to take this opportunity to provide an article on my thoughts and perhaps an updated version of the Layered Architecture Design Pattern for .NET.
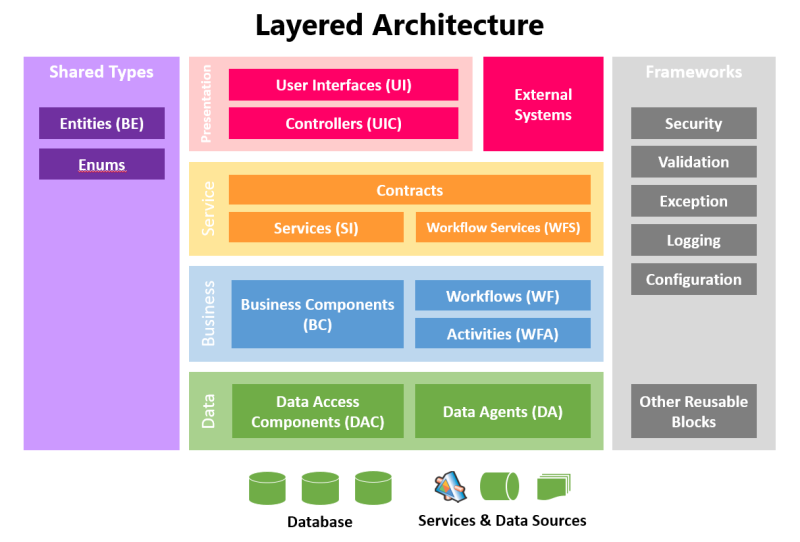
Conceptually, this is how I visualized the Layered Architecture Design Pattern to be, in today's modern world. There are of course more sophisticated visualizations but I purposely kept it simple and near to what most of us are familiar with (and closer to the books).
Data Layer (a.k.a. Data Access Layer or DAL)
The data layer is where we keep our components that handle the insertion (Create), selection (Read), modification (Update) and deletion (Delete) of data - or better known as CRUD operations. While it is simplistic to think that data usually comes from a database, in reality, data can come from or go into various sources as well i.e. Web Services, Flat Files, Message Queues, XML files, SharePoint Lists etc.
Therefore, components that deal with database tables are called Data Access Components (DAC) and those that deal with other data sources will be called Data Agents (DA) i.e. Service Agents, File Agents, Queue Agents etc.
Data Access technologies that you can use in .NET are ADO.NET, Enterprise Library Data Access Application Block and ADO.NET Entity Framework.
Business Layer (a.k.a. Business Logic Layer or BLL)
The business layer is where the heart of our application resides. It contains all the processing logic to make the application possible. The Business Component (BC) is where you put these processing logic where each can be coded into independent business methods. Traditionally, we are required to chain-up the business methods manually in code to form the business process but fortunately today, we have workflow technologies.
If you can isolate each business method to function on its own, you can exposed them as a Workflow Activity (WFA). These workflow activities can then be used by a Workflow (WF) component to orchestrate the business processes.
Windows Workflow Foundation is the workflow technology that can be used in .NET.
Services Layer (a.k.a. Messaging Layer)
The services layer plays the most important role in the architecture to enable the functionality of the system to be exposed to client and external applications. It is also the key to achieving multi-platform and interoperable solutions.
Services components expose the functionality of business components or workflows via Contracts. In the Services-Orientation world, contracts are the interfaces where both service providers and service consumers agree on and should be immutable. Contracts are not just limited to describe the service and its operations but can also be used to describe the messages (i.e. Message Contracts) that are to be sent and received.
I use Services (SI) to represent components that expose business components directly and Workflow Services (WFS) to represent services that expose workflow functionality. The reason for this is because Workflow Services are usually long running and may have special requirements such as correlation.
Services technologies that can be used in .NET are Windows Communication Foundation (WCF), Workflow Services and ASP.NET WEB API.
Presentation Layer (a.k.a. User Interface Layer)
The presentation layer should not need much explanation. It is basically the part of the system where the user interacts with. Your screens, forms, web pages and reports are all User Interfaces (UI) which are part of the presentation layer. User Interfaces can make use of User Process Components or Controllers (UIC) to communicate with the back-end and to navigate or process the UI.
A carefully designed layered application should be able to support any form (or platform) of UI. If you are able to encapsulate all your processing logic behind the service layer, you can have whatever UI (Web, Desktop or Mobile) that you desire to connect to it - even UI-less external systems.
Presentation technologies that can be used in .NET are Windows Presentation Foundation (WPF), Silverlight, ASP.NET Web Forms, ASP.NET MVC, Windows Phone, Windows Store Applications and Windows Forms.
Shared Types
So far we have covered the components in all the layers but we have not yet discussed about how data is being passed between them. Traditionally, .NET developers use DataSets and DataTables but these are heavy-weight objects. Entities are Plain-Old-CLR-Objects (POCO), which means they are just classes with properties that ferry data across your layers. Sometimes, they are also called Data Transfer Objects (DTO).
It is recommended that you do not put any processing logic inside the Entities. If there are any processing logic, they should be placed in the business components. The reason is because when entities are being serialized to non .NET platforms, your processing logic may not carry over.
Some property values in entities can be represented using Enumerations (Enums) for easier readability. Example, it is much better to strongly-type your Status property with an Enum to show meaningful statuses such as Pending, Cancelled or Approved, instead of 0, 1 or 2.
Frameworks (a.k.a. Cross-cutting Framework)
In every system, there are bound to be code that can be shared across all the layers i.e. logging, auditing, validation and etc. You can treat these components as Framework components that can be shared by any of the layers. Framework components can be from 3rd-party (i.e. Microsoft Enterprise Library) or any custom in-house built components i.e. string manipulation functions, custom validation functions, extension methods etc.
Conclusion
I hope the explanation in this article can be a useful foundation for adopting the Layered Architecture Design Pattern. If you wish to see code samples on how it can be implemented with .NET technologies, please feel free to visit Layered Architecture Sample for .NET.